Recommender systems

Recommender Sytems
Introduction
The recommendation technology has become a relatively new research area. The techniques behind this technology have been improved over the time and have made a significant difference in people’s lives. In general, the aim of such system is to provide the relevant information as recommendation in a wide range of web services through analyzing and aggregating the user’s behavior and expectations. The delivered recommendations can facilitate the decision making process for the users who lack sufficient personal experience and expertise. Ultimately, the recommender systems are decision-making systems which will provide relative information easy to manage, adapted to the user’s preferences and interests within a specific domain.
1- Background
Recommender systems, also called recommendation systems (RSs), appeared in the mid-1990s as an independent research area. They play a curial role to represent specific kind of information filtering systems which seek to provide the rating or preference that a user would give to an item he is interested in.
Itemis a usual termwhich is used in the recommendation services or products like movies, books, CDs, etc. It can be represented by a set of features, also called attributes or properties. Each item is characterized by its complexity and its value (i.e. utility). Such values can be positive if its related item is useful for the user or negative if it is not appropriate hence, we can consider, here, that the user made a wrong decision. RSs might also use a range of features and properties of items that can be represented using several information and representation approaches such as a set of attributes or concepts in an ontological representation of a domain.
The primary task of a RS is suggesting items in a personalized manner and considering them in recommendations that best fit their individual needs and tastes. Therefore, it requires that the system must maintain a user’s profile in order to deliver the right recommendations. The RS is also an attempt to automatically model and technically reproduce the process of suggestions in the real world. It can change the way to find what users who lack sufficient experience or knowledge need in term of products and information. For this purpose, it is usually visualized as a knowledge discovery tool as it has the ability to build new recommendations to meet the requirements of its users. Hence, its main objective is to search for and filter the best choices, interests, circumstances and characteristics, considering the user’s profile. In other words, this technology studies different patterns of behavior to comprehend what someone will prefer from a collection of things that he has never faced before. In fact, the good personalized recommendations might add another dimension to the user’s experience and more facilitate their routine decision-making.
2- Data and Information Sources
The variety of information that can be collected about a user and/or an item is very wide. It plays an essential role to establish the efficiency of every recommendation system for the reason that RS might not function accurately in the case where the user model has not been well built. Ultimately, the data sources used in each RS plays a significant role in its evaluation. It can be structured in various ways, whether they can be appropriated or not appropriated to the user’s recommendation. They rely on different types of data where some RSs need this data about the user, some need it about the products and others need both. The most commonly classification of the data is divided as below:
2.1- Explicit Data
Explicit data is a methodology which is based on information and interests input by the users themselves. Usually, the system requires that the user provides ratings for items in order to express his judgements and build his profile (i.e. model). In this context, several approaches have been proposed to construct and update the user’s profile. Generally, the rating approach is one of the highlights method which are used to predict the user’s personality. It can take several forms as follow:
Numerical: This formrepresents a rating on a discrete scale like the 1-5 stars used in Amazon.com. This rating form can be described as follow: 1-star: I hate it; 2-stars: I don’t like it; 3-stars: It’s OK; 4-stars: I like it; 5-stars: I love it.
Ordinal: In the most cases, this form is used via questionnaire where the customer is asked to indicate his opinions about an item as follow:1-strongly agree; 2- agree; 3-neutral; 4-disagree; 5-strongly disagree.
Binary: This form is used to simply ask the user about his opinions for a collection of item while the user should not express his degree of interests, he just accepts or refuses the itemby saying this item is good or it is bad.
Unary: This form indicates that the user has selected or rated an item positively. The absence of a rating assumes that we have no information relating the user to the item.
2.2- Implicit Data
In most cases, it is not necessary that users rate all items they have bought or viewed because they spend their time rating items or do not see the point of doing. Hence, it is necessary to overcome the lack of the sufficient information in seeking to construct the user’s model. For this purpose, we can infer an implicit rating via studying different patterns behaviors about the user where the system deduces their information by analysing server logs, the time spent on a particular web page or search and browsing history.
3- General Process
Aswe mentioned before, the recommendation approaches can be classified according to the data sources they use. This data can be acquired in different ways and it is also characterised by three sources types of information that can be used in the recommendation process which are the item data (e.g. keywords), the user data (e.g. age, types, level of studies) and the user-item ratings (e.g. obtained from transaction data, explicit ratings).
The success of each RS depends on its ability to represent user’s potential interests accurately. Obviously, it is necessary to keep a profile with updated information about the user’s preferences to decide which items suit better his/her taste. By these means, RSs collect relevant information about their users to generate their corresponding profiles for the prediction tasks of behaviors or content of the resources the user accesses. Generally, every RS follows a specialized process in order to provide recommendations as follow:
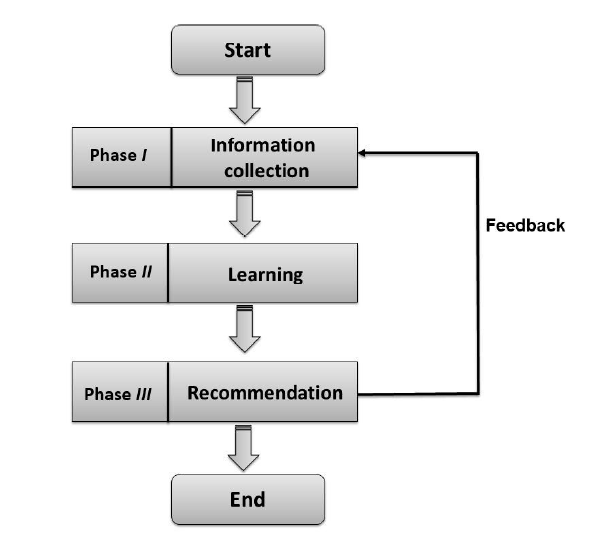
Information collection phase: As a first step in the recommendation process, RS requires to collect as much information as possible about each user to build a user profile or a user model which contains user’s interests, opinions, preferences and cognitive skills in order to provide reasonable recommendations.
Learning phase: This step is represented as a discover and pattern phase. It is used to filter and exploit the user’s interests from the feedback gathered in information collection phase.
Prediction/Recommendation phase: This step recommends what kind of items the user may prefer. The recommendation phase is used to match he user’s preferences and the items which compromise the highest scores discovered in the two previous phases.
Satisfaction degree/Feedback: This step is used to measure the impact of the users’ feedback about the recommendations. It is also a method to collect more information about users to provide more satisfactory recommendations in the future.
4- Major Recommendation Approaches
RSs have been actively and extensively studied over the years. They present a multidisciplinary field which is supporting individuals who lack sufficient personal skills to evaluate overwhelming number of alternative items that an online website can offer in finding items of interest. The choice of such RS approach has an important effect upon user satisfaction. Usually, themost popularwebsites apply RS to personalize the online store for each user but they can also apply non personalized way for recommendations.
The personalized filtering is a technique which is mostly used in seeking to predict the user’s personality and to derive its personality based item preferences. It is represented as ranked lists of items which are based on the user’s preferences. Thus, it can infer the user’s preferences not only by the initial information that he provides explicitly, but also by analysing his profile and comparing it with similar profiles.
The non-personalized recommendations are represented as the most simple recommendation approach. It recommends the suitable items that are based on the viewpoints or the feedback of other users on average. Hence, the realisation of this approach is very simple because the data is easy to collect. Moreover, this automatic systems do not require an interaction between the user and the system, so they do not require also a user’smodel. In addition, each recommendation is completely independent of the user, so the recommendations may be identical for each one. Generally, this approach can be based on the top-N items or the popularity of items (e.g. average ratings, sales data and total visits).
It is very important to use the efficient recommendation techniques in order to provide the best and useful suggestions for users. For this reason, it is important to understand which information will be exploited by the system and when it will be generated. In general, experts classify these techniques into several categories by analysing and filtering the data sources through Internet according to multiple criteria like user preferences and types of feedbacks.
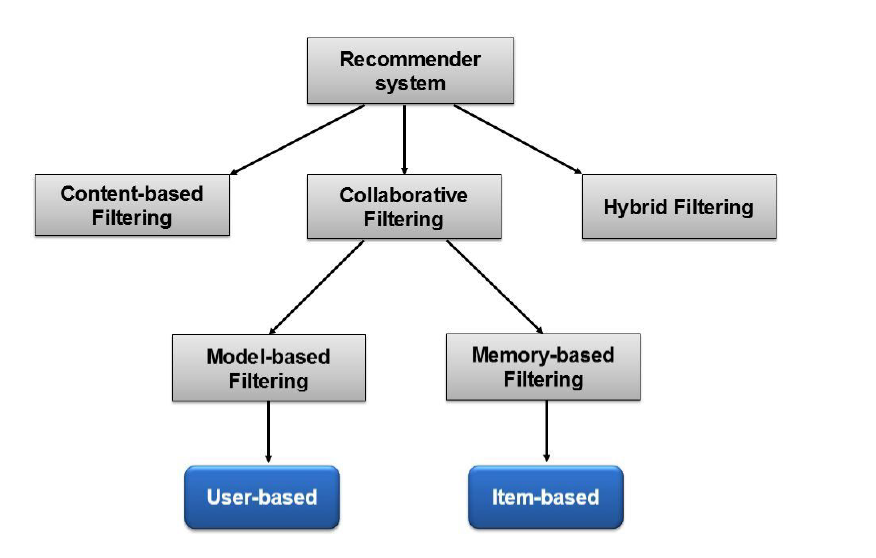
The content-based, collaborative filtering and hybrid approaches are broadly considered as the most important and familiar ones. The content-based filtering is a technique which retrieves items similar to the user’s profile, whereas the collaborative filtering technique allows to identify users with similar preferences to the given user’s preferences and recommend items they have liked. For the last types, it represents a combination between the two previous approaches in order to overcome their weaknesses. In the next subsections, we will discuss the features and the main proposals of each recommendation technique.
4.1- Content-based Recommender System
Content-based (CB) recommender system focuses on content or description of items in seeking to suggest recommendations fromthe user’s preferences profiles. This filtering technique allows to collect the user’s information by analyzing the user’s behavior or by asking the user explicitly about his priorities in order to construct a user’s model. The key component of this technique is the construction of the user’s model from the user’s preferences. Therefore, RS must require several information about the user’s interaction with RS and even about the user’s history.
The content-based filtering technique considers the user queries and the items contents in their recommendations and ignores any contributions coming from third part like the case of collaborative technique. The delivered recommendations, here, are just provided according to the interaction between the system and the user’s profile. Furthermore, the CB recommendation can be also based on the items which are already rated positively by the user in the past in order to compare them with the items that he has not rated yet. Hence, the recommendations are represented in the formof similar items that a given user has yet liked.
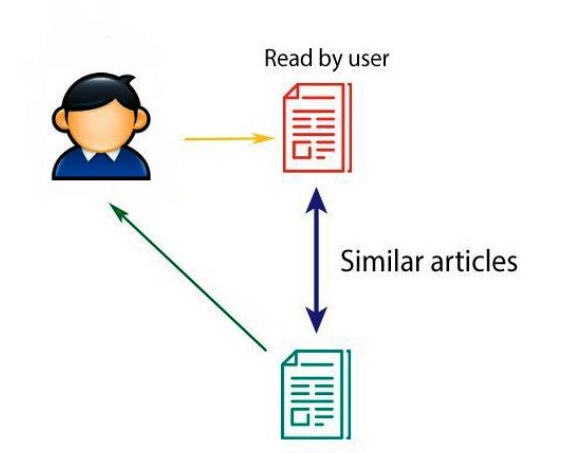
User independence is considered as an important aspect of CBF recommendation. It has the capability to recommend item with unique taste provided by an active user using ratings. More specifically, the active user does not need data from other users, his recommendation will be just based on his own preferences. Further, we can consider transparency as an other advantage of CBF. Using this feature, RSs can provide explanations for recommended items by listing content-features that caused an item to be recommended. Next advantage of CBF that is called new item, CB recommendation, here, can suggested items before being rated for an important number of users.
The CBF methods are also suffer from various limitations. Generally, the CBF approach is mostly dependent on items’ metadata. Therefore, it requires rich description about items in order to discriminate the taste of the user and construct a good user profile for him. This problem is called limited content analysis. We can also mention the content over-specialization as another serious problem of CBF technique. It recommends suggestionswith a limited degree of novelty for the reason that is not possible to have suggestions not already aware. The recommended items, here, are characterised by very high scores which are mostly similar to the items already positively rated.
4.2- Collaborative Recommender System:
The collaborative filtering techniques (CF) is considered as the most popular implemented techniques in RSs. CF is a process of filtering information which provides collaboration among various data sources, agents, viewpoints, etc. This algorithmcan recommend items that the user has not rated before, but that were positively rated by users in neighborhood in the past.
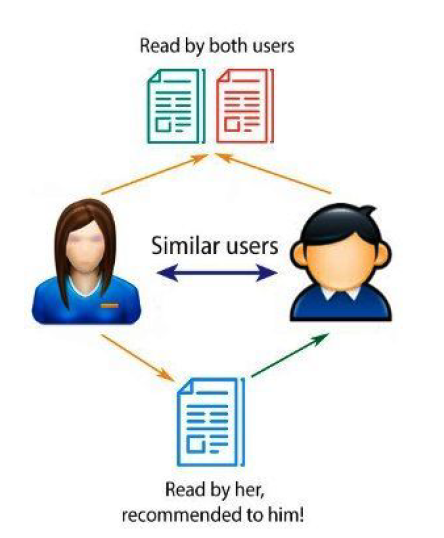
In the recommendation systems, the CF methods is widely divided into two categories user-based CF and item-based CF.
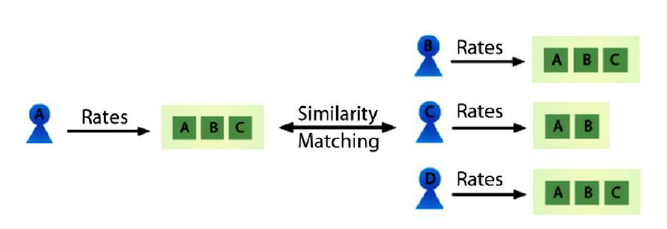
User-based collaborative filtering: This approach computes the correlation with all other users for each item and aggregate the rating of highly correlated users as depicted in figure below.
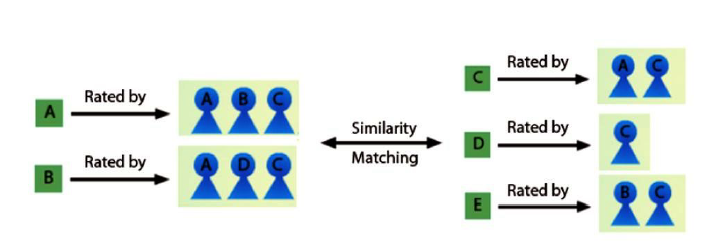
Item-based collaborative filtering: This approach computes for each user item the correlation with all other items and aggregates for each user the ratings for items that are already highly correlated as depicted in this figure.
The CF technique has some major advantages over CBF in that it can perform in domains where there is not much content associated with items and the content is difficult to analyze for the computer system. Thus, we should mention that the CF technique is just based on groups of users with similar preferences in the recommendation process and it does not require the representation of items. So, it has the ability to provide relevant recommendations without using the content in the user’s profile. Despite its success, their widespread has revealed some potential problems such as:
Cold-start problem, it is one of the major problems which reduces the efficiency and the performance of every RS. It presents the case where a RS does not have an adequate information about an item or a user in order to make relevant predictions. Hence, the user’s profile will be empty since the user has not rated any item before and the taste is not identified.
Data sparsity problem, it is considered as a result of the lack of insufficient information when only few items of the total information available in a database are rated by the users.
Synonymy, it is that some added terms may have different meanings from what is intended, which sometimes leads to rapid degradation of recommendation performance. Mostly, RSs find synonymy difficult to deduce distinction between closely related items. They apply different methods to overcome this problemlike the construction of thesaurus, automatic termexpansion and Latent Semantic Indexing.
4.3- Hybrid Recommender System:
It is another important approach of RSs which overcomes the weaknesses of the two other approaches. It combines two or more recommendations techniques to obtain a better optimization reducing the limitations of pure recommendation systems. The idea behind hybrid approach is that a combination of techniques will provide more effective suggestions than a single algorithm as the drawbacks of one algorithm can be overcome by another one. Thus, Themost popular hybrid approaches are those of the system based on content and the system based on collaborative. This combination of approaches can proceed in different ways:
- Separate implementation of algorithms and joining the results.
- Utilize some rules of content-based filtering in collaborative approach.
- Utilize some rules of collaborative filtering in content-based approach.
- Create a unified RS that brings together both approaches.
The most important advantage of this hybridized system is being characterised by a high accuracy recommendations unlike the other techniques. This technique is also considered as a solution of a cold start problem due to short user profiles and the availability of sparse ratings of a user that can be handled effectively by using hybrid recommendation system. The hybridized approach achieves several strategies which are broadly classified as follow:
Weighted: The score of different recommendation components are combined together to provide a single suggestion.
Switching: The system chooses among recommendation components and applies the selected one depending on the current situation.
Mixed: Recommendations fromdifferent recommenders are presented at the same time.
Feature Combination: Features derived from several data sources are combined together and given to a single recommendation algorithm.
Feature Augmentation: One recommendation technique is used to compute a feature or a set of features, which is then used as an input to another technique.
Cascade: Recommenders refines the recommendations given by another technique.
Meta-level: One recommendation technique is applied and produces some sort of model’s, which are then the input used by the next technique.
5- Properties of Recommender Systems:
The success of each RS depends on the efficiency that can be measured in terms of RSs properties. In order to specify the performance of such system, we should measure the closeness of the estimated preferences and the actual preferences of a user. Different approaches have been adopted several properties to evaluate the performance of recommendation systems like accuracy, privacy, diversity, etc. It is important to highlight that we should consider the existed trade-off present between properties to establish a good evaluation. For instance we can consider accuracy less important to some others properties like diversity or privacy and vice versa. In this section, we mention some properties of RSs to clarify their impacts on users like:
User preference: It allows to provide a list of ranked items through an important number of existing products. This property aims at supporting user to find and collect knowledge about themost suitable product efficiently andmore quickly.
Prediction Accuracy: The main objective of this property is to suggest accurate recommendations that are represented as the most suitable ones for the user. This property is related to a prediction engine which delivers the items that present the user’s opinions and interests.
Privacy: Using this property, the recommender should establish the privacy of the user’s profiles and preferences. The main objective of this property is to deliver secret recommendations where no third party can access and use the profile of a specific user.
Trust: It refers to the users trust in the recommendations provided by RS. To enhance trust, RS recommends some reasonable items which are already selected and known in order to increase trust in the system recommendations for unknown items as well as the interaction between the system and the user is the basis of building this trust.
Robustness: It is related to the stability of the recommendation in the presence of fake information typically inserted on purpose in order to influence the recommendations. RS should create a system which is immune to any type of unrealistic attack. In this context, the attack refers to the influence used by injecting fake users’ profiles to influence and to try changing the rating of an item.
Novelty: Novel recommendations are the recommendations of products or services which the user did not select or know yet. The best approach to deliver novel recommendations is not to filter out items but to collect the information that could be implemented. Thus, RS can also recommend popular items less likely in order to deliver for their user a novel recommendation.
Serendipity: It is a pleasant surprise of recommendation system results. For instance, a user has ranked a list of his preferred songs, the system recommends him a new song which may be new, so the user will be surprised because he may not be informed about it. In some cases, the random suggestions may be surprise and satisfy the user but it should require the balance between the accuracy and the serendipity.
Diversity: It is commonly defined as the average pairwise distance between recommendations to users. The diversification of these recommendations aims at enhancing the user’s experience and expertise. Frequently, the algorithms proposed in the RSs literature allow to maximize the recommendations accuracy. However, in most cases, recommending a set of similar items is insufficient and not profitable for the users, and it is not enough to judge the effectiveness of RSs. It can also causing user dissatisfaction and frustration. Therefore, the key of these situations is should be consider diversity to meet user’s satisfaction.