Large Language Models Learning Techniques: A Comprehensive Guide
Introduction
In the rapidly advancing field of Artificial Intelligence, large language models (LLMs) have emerged as indispensable tools for natural language understanding and generation. However, deploying these powerful models effectively requires understanding and applying the right adaptation techniques. Various methodologies have been developed to enhance and customize LLM capabilities, each serving specific use cases and constraints.
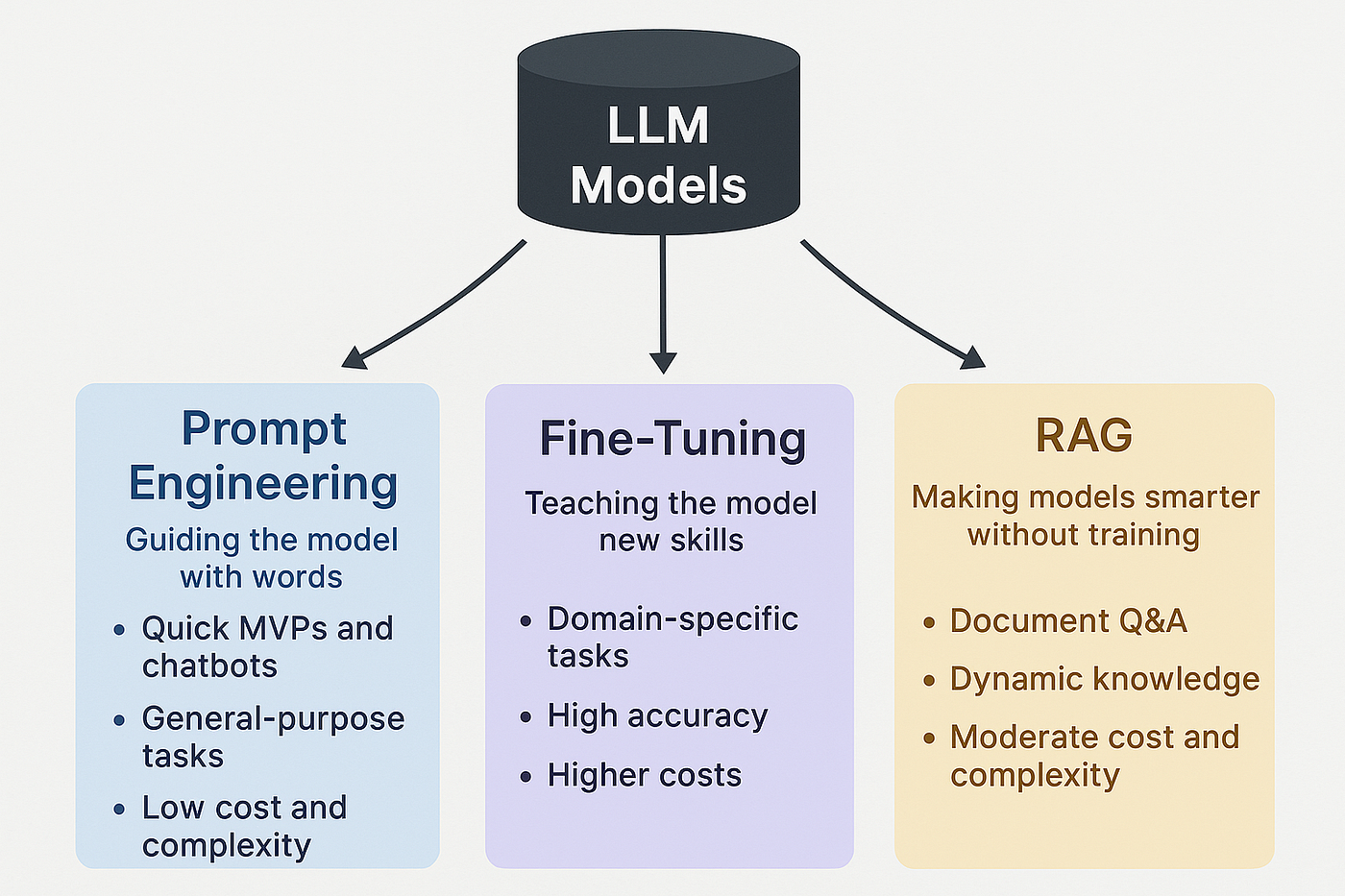
This comprehensive guide explores three fundamental approaches to working with LLMs:
- Prompt Engineering: Zero-training adaptation through strategic input design
- Retrieval-Augmented Generation (RAG): Enhancing models with external knowledge
- Fine-Tuning: Adapting model parameters to specific tasks and domains
Understanding when and how to apply these techniques is crucial for building effective, efficient, and cost-optimized LLM applications. Whether you’re building a chatbot, creating a domain-specific assistant, or developing enterprise AI solutions, this guide will help you navigate the landscape of LLM adaptation strategies.
Prompt Engineering: The Art of Communication with LLMs
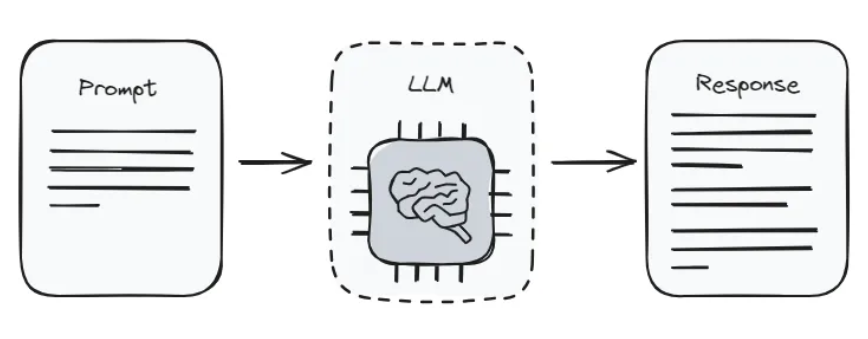
Prompt engineering is the strategic design of input prompts to direct the behavior of AI language models without modifying their underlying parameters. These carefully crafted prompts serve as structured instructions, guiding models to produce outputs tailored to specific tasks—from summarizing documents and answering questions to generating creative content and writing code.
Why Prompt Engineering Matters
Prompt engineering offers several compelling advantages:
- Zero cost: No training infrastructure or datasets required
- Immediate results: Instant iteration and testing
- Flexibility: Easy to modify and adapt for different use cases
- Accessibility: Anyone can experiment without ML expertise
- Model-agnostic: Works across different LLMs (GPT-4, Claude, Gemini, etc.)
Core Prompt Engineering Techniques
1. Zero-Shot Prompting
Direct instruction without examples. The simplest approach but requires clear, explicit instructions.
Example:
1
2
3
4
5
Classify the following email as spam or not spam:
"Congratulations! You've won $1,000,000. Click here to claim."
Classification:
Best for: Simple tasks, well-defined objectives, general knowledge queries
2. Few-Shot Learning (In-Context Learning)
Providing examples that demonstrate the desired output format and behavior. This technique dramatically improves accuracy for specific patterns.
Example:
1
2
3
4
5
6
7
8
9
10
Extract key information from customer feedback:
Feedback: "The product arrived late but quality is excellent"
Sentiment: Mixed | Issue: Delivery | Positive: Quality
Feedback: "Fast shipping, but product broke after 2 days"
Sentiment: Negative | Issue: Durability | Positive: Shipping
Feedback: "Amazing product, works perfectly and arrived on time"
Sentiment: [Model completes]
Best practices:
- Use 3-5 diverse examples covering edge cases
- Keep examples concise but representative
- Order examples from simple to complex
- Ensure consistency in format across examples
3. Chain-of-Thought (CoT) Prompting
Encouraging the model to show its reasoning process step-by-step, dramatically improving performance on complex reasoning tasks.
Example:
1
2
3
4
5
6
7
8
9
Problem: A store has 15 apples. It sells 40% in the morning and 3 more in the afternoon. How many apples remain?
Let's solve this step by step:
1. Calculate 40% of 15: 15 × 0.40 = 6 apples
2. Apples after morning: 15 - 6 = 9 apples
3. Apples sold in afternoon: 3
4. Final count: 9 - 3 = 6 apples
Answer: 6 apples remain.
Performance boost: CoT can improve accuracy by 20-30% on math and reasoning tasks.
4. Role-Based Prompting
Assigning the model a specific role or persona to shape its responses.
Examples:
1
2
3
4
5
6
7
8
You are an expert Python developer with 10 years of experience.
Provide code review feedback for this function...
You are a patient elementary school teacher explaining concepts simply.
Explain how photosynthesis works...
You are a professional business consultant.
Analyze this company's quarterly report...
5. Structured Output Prompting
Requesting responses in specific formats (JSON, tables, lists) for easier parsing and integration.
Example:
1
2
3
4
5
6
7
8
9
10
11
12
Analyze this product review and return a JSON object:
Review: "Great laptop, fast performance, but battery life is disappointing"
Format:
{
"overall_sentiment": "positive/negative/neutral",
"aspects": [
{"feature": "...", "sentiment": "...", "mentioned": true/false}
],
"rating": 1-5
}
6. Prompt Templates
Reusable patterns that can be adapted for various inputs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Template for summarization:
"Summarize the following [document type] in [X] sentences,
focusing on [key aspects]:
[Content]
Summary:"
Template for classification:
"Classify the following [item] into one of these categories:
[category list]
[Item to classify]
Category:
Reason:"
Advanced Prompt Engineering Strategies
Prompt Chaining
Breaking complex tasks into sequential steps, where each prompt’s output feeds into the next.
1
2
3
Step 1: Extract key claims from article
Step 2: Fact-check each claim individually
Step 3: Synthesize findings into final report
Self-Consistency
Generating multiple responses and selecting the most frequent answer to improve reliability.
Iterative Refinement
Asking the model to critique and improve its own outputs:
1
2
3
1. Generate initial response
2. "Review the above answer. What could be improved?"
3. "Now provide an improved version addressing those issues."
Limitations and Considerations
Challenges:
- Brittleness: Small prompt changes can dramatically affect results
- Inconsistency: Same prompt may yield different outputs across runs
- Context limits: Restricted by model’s context window (4K-200K tokens)
- No learning: Model doesn’t improve from interactions
- Prompt injection: Security vulnerabilities from malicious inputs
When prompt engineering isn’t enough:
- Tasks requiring specialized domain knowledge not in training data
- Need for consistent, deterministic outputs
- Handling proprietary or confidential information
- Tasks requiring model to learn from user-specific data
Best Practices
- Be specific and explicit: Vague prompts yield vague results
- Provide context: More context generally improves quality
- Use delimiters: Clearly separate instructions from content (```, —, ###)
- Specify output format: Define structure, length, and style
- Test iteratively: Experiment with variations
- Use system messages: Set global behavior (when supported)
- Add constraints: Specify what to avoid or limits to respect
- Request explanations: “Explain your reasoning” improves transparency
Real-World Applications
- Customer Support: Query classification and response generation
- Content Creation: Blog posts, social media, marketing copy
- Code Assistance: Code generation, debugging, documentation
- Data Extraction: Parsing unstructured text into structured data
- Translation: Language translation with style preservation
- Education: Tutoring, explanation generation, quiz creation
Retrieval-Augmented Generation (RAG): Grounding LLMs in Knowledge
Retrieval-Augmented Generation (RAG) represents a paradigm shift in how we deploy LLMs, combining the generative power of language models with the precision of information retrieval systems. Rather than relying solely on the model’s parametric knowledge (learned during training), RAG dynamically retrieves relevant information from external knowledge sources and incorporates it into the generation process.
Why RAG Matters
RAG addresses several critical limitations of standalone LLMs:
- Hallucination reduction: Grounds responses in retrieved evidence rather than potentially incorrect memorized patterns
- Knowledge freshness: Incorporates up-to-date information without retraining
- Source attribution: Provides citations and references for transparency
- Domain specialization: Access to proprietary or domain-specific knowledge
- Cost efficiency: Updates knowledge base instead of expensive model retraining
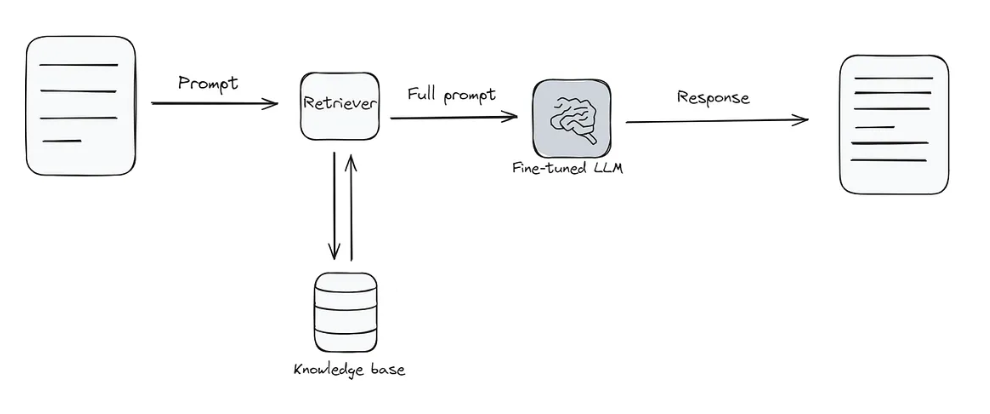
RAG Architecture: End-to-End Pipeline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
User Query
↓
┌─────────────────────────────────────────┐
│ 1. Query Processing & Embedding │
│ - Parse query │
│ - Generate query embedding │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 2. Retrieval │
│ - Semantic search in vector DB │
│ - Retrieve top-k relevant chunks │
│ - Optional: Re-ranking │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 3. Context Assembly │
│ - Format retrieved documents │
│ - Augment original query │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 4. Generation │
│ - LLM generates response │
│ - Grounded in retrieved context │
└─────────────────────────────────────────┘
↓
Answer with Sources
Core Components Explained
1. Document Processing (Indexing Phase)
Chunking Strategy: Breaking documents into manageable pieces is crucial for retrieval quality.
- Fixed-size chunks: 200-500 tokens with 50-100 token overlap
- Sentence-based: Split on sentence boundaries for coherence
- Semantic chunking: Use NLP to identify logical sections
- Recursive splitting: Split by paragraphs, then sentences, then words
Example chunking:
1
2
3
4
5
6
7
8
# Pseudo-code
original_document = load_document("company_handbook.pdf")
chunks = split_into_chunks(
document=original_document,
chunk_size=300, # tokens
overlap=50, # tokens
method="recursive"
)
Embedding Generation: Convert text chunks into dense vector representations.
Popular embedding models:
- OpenAI ada-002: 1536 dimensions, excellent general-purpose
- Sentence-Transformers: Open-source, various sizes (384-1024 dims)
- E5: State-of-the-art open model for semantic search
- BGE: Efficient, high-quality embeddings
Indexing: Store embeddings in a vector database for fast similarity search.
2. Retrieval Techniques
Semantic Search (Dense Retrieval): Use embedding similarity (typically cosine similarity) to find relevant documents.
1
2
3
4
5
6
7
8
query_embedding = embed("How do I reset my password?")
# Find top-k most similar document chunks
results = vector_db.search(
query_embedding,
top_k=5,
similarity_metric="cosine"
)
Hybrid Search: Combine semantic search with keyword-based retrieval (BM25) for better recall.
1
2
3
4
5
semantic_results = dense_retrieval(query)
keyword_results = sparse_retrieval(query) # BM25
# Combine and rerank
final_results = rerank(semantic_results + keyword_results)
Advanced Retrieval Strategies:
- HyDE (Hypothetical Document Embeddings):
- Generate hypothetical answer first
- Use it for retrieval instead of original query
- Often improves retrieval quality
- Query Expansion:
- Generate multiple query variations
- Retrieve for each variation
- Aggregate results
- Multi-hop Retrieval:
- Retrieve documents
- Extract key entities
- Retrieve again based on entities
- Useful for complex questions requiring multiple sources
3. Re-ranking
Improve retrieval precision by re-scoring initial results.
Cross-encoder re-ranking:
1
2
3
4
5
6
7
8
9
10
11
# Initial retrieval: 20 candidates (fast but less accurate)
initial_results = vector_db.search(query, top_k=20)
# Re-rank with cross-encoder (slower but more accurate)
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
scores = reranker.predict([
(query, doc.content) for doc in initial_results
])
# Return top-5 after re-ranking
final_results = sort_by_score(initial_results, scores)[:5]
4. Context Assembly
Format retrieved information for LLM consumption.
Example prompt template:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
You are a helpful assistant. Answer the question based on the context below.
If you cannot answer based on the context, say "I don't have enough information."
Context:
---
[Retrieved Document 1]
Source: company_policy.pdf, Page 15
[Retrieved Document 2]
Source: employee_handbook.pdf, Page 42
---
Question: {user_query}
Answer:
Vector Databases: The Foundation of RAG
Popular options:
| Database | Type | Strengths | Use Case |
|---|---|---|---|
| Pinecone | Managed | Easy setup, scalable | Production apps, fast prototyping |
| Weaviate | Open-source | GraphQL, flexible schema | Knowledge graphs, complex queries |
| Milvus | Open-source | High performance, distributed | Large-scale, high-throughput |
| Chroma | Embedded | Lightweight, simple API | Development, small projects |
| Qdrant | Open-source | Rust-based, fast, filters | Production with complex filtering |
| FAISS | Library | Extremely fast, in-memory | Research, benchmarking |
RAG Implementation Patterns
Simple RAG (Naive)
1
2
3
4
5
1. Embed user query
2. Retrieve top-k documents
3. Concatenate with query
4. Send to LLM
5. Return response
Pros: Simple, fast
Cons: May retrieve irrelevant context, no verification
Advanced RAG
Enhancements for production systems:
Query Transformation:
1
2
3
4
5
6
7
8
9
10
11
12
# Original query
query = "latest pricing changes"
# Generate better search queries
transformed = [
"What are the most recent pricing updates?",
"Price changes in the last quarter",
"Current pricing structure"
]
results = [retrieve(q) for q in transformed]
context = deduplicate_and_rank(results)
Self-RAG (Self-Reflective RAG):
1
2
3
4
5
6
1. Retrieve documents
2. LLM decides if retrieval is helpful
3. If yes: generate answer using context
4. If no: generate from parametric knowledge
5. Self-critique: "Is this answer accurate?"
6. If needed: retrieve again with refined query
Iterative RAG:
1
2
3
4
5
1. Initial retrieval and generation
2. Extract uncertain claims from generation
3. Retrieve specifically for those claims
4. Regenerate with additional context
5. Repeat if necessary
RAG Performance Metrics
Retrieval Quality:
- Precision@k: Percentage of retrieved documents that are relevant
- Recall@k: Percentage of relevant documents that were retrieved
- MRR (Mean Reciprocal Rank): Position of first relevant result
- NDCG: Ranking quality considering graded relevance
Generation Quality:
- Faithfulness: Does answer align with retrieved context?
- Answer relevance: Does it address the question?
- Context utilization: Is retrieved information used effectively?
Real-World Applications
1. Enterprise Search & Knowledge Management
1
2
3
Use case: Employee asks "What is our remote work policy?"
- Retrieve from: HR policies, announcements, FAQs
- Answer with citations to specific policy documents
2. Customer Support
1
2
3
Use case: "How do I upgrade my subscription?"
- Retrieve from: Documentation, past tickets, knowledge base
- Provide step-by-step answer with links
3. Legal/Medical Document Analysis
1
2
3
Use case: "Find precedents for intellectual property cases"
- Retrieve from: Case law database, legal documents
- Summarize relevant cases with citations
4. Code Documentation Assistance
1
2
3
Use case: "How do I use the authentication API?"
- Retrieve from: API docs, code examples, GitHub issues
- Generate code snippet with explanation
Challenges and Solutions
Challenge 1: Poor Retrieval Quality
- Solution: Improve embeddings, use hybrid search, implement re-ranking
Challenge 2: Context Window Limits
- Solution: Better chunking, summarize retrieved docs, use long-context models
Challenge 3: Conflicting Information
- Solution: Source weighting, recency scoring, explicit conflict resolution
Challenge 4: Latency
- Solution: Caching, approximate nearest neighbor search, parallel retrieval
Challenge 5: Cost
- Solution: Optimize chunk size, cache common queries, efficient re-ranking
RAG vs Fine-Tuning: When to Use What
Use RAG when:
- Knowledge changes frequently
- Need source attribution
- Working with large document collections
- Want to update knowledge without retraining
Use Fine-Tuning when:
- Need specific response style/format
- Task-specific behavior required
- Knowledge is stable
- Proprietary data must be internalized
Use Both (RAG + Fine-Tuning) when:
- Domain-specific knowledge + specialized behavior
- Example: Medical diagnosis system (fine-tuned on medical reasoning + RAG for latest research)
Fine-Tuning: Adapting LLMs to Specialized Tasks
Fine-tuning is a transfer learning technique that adapts pre-trained language models to specific tasks, domains, or behaviors by continuing training on task-specific data. Unlike prompt engineering (which works with frozen models) or RAG (which augments with external data), fine-tuning actually modifies the model’s parameters to internalize new knowledge and behaviors.
Why Fine-Tune?
Key benefits:
- Task specialization: Dramatically improve performance on specific tasks
- Style consistency: Learn specific writing styles, formats, or tones
- Domain expertise: Internalize specialized vocabulary and knowledge
- Behavior customization: Teach specific reasoning patterns or output structures
- Efficiency at inference: No retrieval overhead, faster responses
- Proprietary knowledge: Embed confidential data without external storage
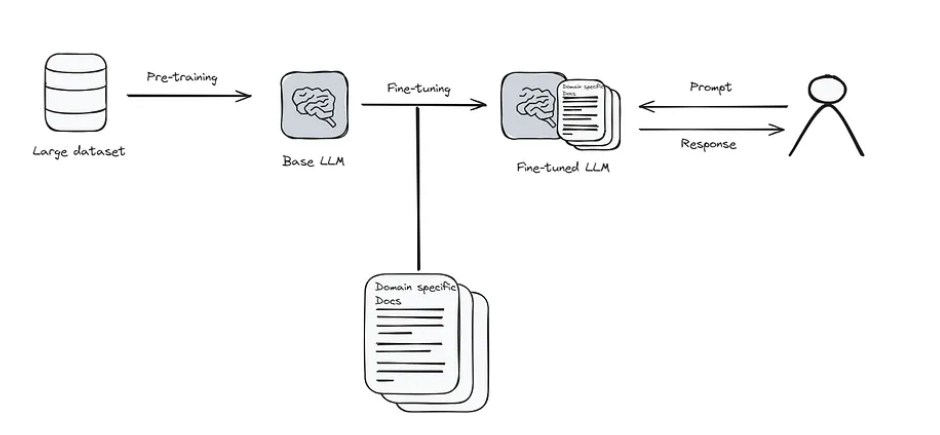
Types of Fine-Tuning
1. Full Fine-Tuning (Traditional Approach)
Update all model parameters on task-specific data.
Process:
1
2
3
4
5
6
7
Pre-trained Model (175B parameters)
↓
Freeze: None (all parameters trainable)
↓
Train on Task Data (10K-100K examples)
↓
Fine-tuned Model
Advantages:
- Maximum performance improvement
- Complete customization possible
- Can dramatically change model behavior
Disadvantages:
- Extremely expensive (requires high-end GPUs)
- Risk of catastrophic forgetting (losing general capabilities)
- Requires large datasets (10K+ examples)
- Long training times (hours to days)
- Storage intensive (full model copy per task)
Typical costs:
- GPT-3 scale (175B): ~$100K+ per fine-tuning run
- LLaMA 70B: ~$10K-50K per run
- Smaller models (7B): ~$500-2K per run
2. Parameter-Efficient Fine-Tuning (PEFT)
Modify only a small subset of parameters while keeping most of the model frozen.
Key insight: You don’t need to update all billions of parameters to adapt a model. Small, strategic modifications can achieve 95%+ of full fine-tuning performance while using <1% of the parameters.
Popular PEFT Methods
LoRA (Low-Rank Adaptation)
The most popular PEFT technique. Instead of updating weight matrices directly, inject trainable low-rank matrices.
How it works:
1
2
3
4
5
6
7
8
9
10
Original weight matrix: W (4096 × 4096) → 16M parameters
LoRA approach:
W_adapted = W_frozen + A × B
Where:
A: (4096 × 8) = 32K parameters
B: (8 × 4096) = 32K parameters
Trainable parameters: 64K (0.4% of original!)
Advantages:
- 99% parameter reduction: Train 8M instead of 7B parameters
- Fast training: 3-10x faster than full fine-tuning
- Low memory: Fits on consumer GPUs (RTX 3090, 4090)
- Modular: Swap LoRA adapters for different tasks
- No quality loss: Matches full fine-tuning performance
Configuration example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8, # Rank (higher = more capacity, more params)
lora_alpha=32, # Scaling factor
target_modules=["q_proj", "v_proj"], # Which layers to adapt
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(base_model, config)
print(f"Trainable params: {model.print_trainable_parameters()}")
# Output: trainable params: 8M || all params: 7B || trainable%: 0.11%
When to use:
- Limited GPU resources
- Multiple task-specific versions needed
- Quick iteration and experimentation
- Most general fine-tuning scenarios
QLoRA (Quantized LoRA)
LoRA + 4-bit quantization for extreme memory efficiency.
Innovation: Load base model in 4-bit precision, train LoRA adapters in full precision.
Memory comparison (7B model):
- Full fine-tuning: ~80GB VRAM
- LoRA: ~18GB VRAM
- QLoRA: ~8GB VRAM (fits on RTX 3090!)
Use case: Fine-tune large models on consumer hardware.
Other PEFT Methods
Prefix Tuning:
- Add trainable prompt tokens before input
- Model learns optimal “soft prompts”
- Very few parameters (0.01-0.1% of model)
Adapter Layers:
- Insert small trainable modules between frozen layers
- Bottleneck architecture (e.g., 4096→256→4096)
- ~1-3% additional parameters
IA³ (Infused Adapter by Inhibiting and Amplifying Inner Activations):
- Learn scaling vectors for activations
- Even fewer parameters than LoRA
- Good for simple adaptations
Fine-Tuning Workflow
Step 1: Data Preparation
Data format example (instruction tuning):
1
2
3
4
5
6
7
8
9
10
11
12
[
{
"instruction": "Classify the sentiment of this review",
"input": "This product exceeded my expectations!",
"output": "Positive"
},
{
"instruction": "Translate to French",
"input": "Good morning",
"output": "Bonjour"
}
]
Data requirements:
- Minimum: 100-500 examples (for simple tasks with PEFT)
- Recommended: 1K-10K examples (for robust performance)
- Optimal: 10K-100K examples (for complex tasks)
Quality over quantity: 1,000 high-quality examples > 10,000 noisy ones
Data quality checklist:
- ✓ Representative of target use cases
- ✓ Diverse in input patterns
- ✓ Consistent in format and style
- ✓ Balanced across categories/tasks
- ✓ Cleaned of errors and biases
Step 2: Training Configuration
Key hyperparameters:
1
2
3
4
5
6
7
8
9
10
training_args = {
"learning_rate": 2e-4, # Higher than pre-training (1e-5)
"num_epochs": 3, # Usually 1-5 epochs
"batch_size": 4, # Per device, adjust for VRAM
"gradient_accumulation": 4, # Effective batch_size = 16
"warmup_steps": 100, # Gradual learning rate increase
"weight_decay": 0.01, # Regularization
"max_grad_norm": 1.0, # Gradient clipping
"fp16": True, # Mixed precision training
}
Training time estimates (LoRA, 7B model, 5K examples):
- 1x A100: ~2-4 hours
- 1x RTX 4090: ~4-8 hours
- 1x RTX 3090: ~6-12 hours
Step 3: Monitoring and Evaluation
Metrics to track:
- Training loss: Should decrease smoothly
- Validation loss: Watch for overfitting (if val loss increases while training loss decreases)
- Task-specific metrics: Accuracy, F1, BLEU, ROUGE, etc.
- Perplexity: Lower is better (measures prediction confidence)
Early stopping: Stop when validation performance plateaus or degrades.
Step 4: Deployment
LoRA adapter deployment:
1
2
3
4
5
6
7
8
9
10
from peft import PeftModel
# Load base model
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
# Load LoRA adapter (only ~10MB!)
model = PeftModel.from_pretrained(base_model, "./lora-adapter")
# Inference
output = model.generate(**inputs)
Benefits: Share base model across tasks, swap adapters as needed.
Fine-Tuning Strategies by Use Case
1. Instruction Tuning
Goal: Teach model to follow diverse instructions.
Data format:
1
2
3
Instruction: Summarize this article in 3 sentences.
Input: [Long article text]
Output: [3-sentence summary]
Dataset size: 10K-50K diverse instructions
Method: LoRA on Llama-2 or Mistral
Result: General-purpose instruction-following assistant
2. Domain Adaptation
Goal: Learn specialized vocabulary and concepts (medical, legal, financial).
Data: Domain-specific documents and Q&A pairs
Method: Full fine-tuning or LoRA with higher rank (r=16-32)
Example: Med-PaLM (medical), BloombergGPT (finance)
3. Style/Tone Adaptation
Goal: Match specific writing style or brand voice.
Data: 500-5K examples in target style
Method: LoRA with low rank (r=4-8)
Use case: Customer support (friendly tone), legal writing (formal tone)
4. Task-Specific Fine-Tuning
Goal: Optimize for narrow task (classification, NER, summarization).
Data: 1K-10K labeled examples
Method: LoRA or full fine-tuning
Benefit: Often beats zero-shot by 20-40%
Advanced Techniques
Continued Pre-Training
Before task-specific fine-tuning, continue pre-training on domain documents.
1
2
3
1. Continued pre-training: Medical textbooks (unlabeled)
2. Instruction tuning: Medical Q&A pairs (labeled)
3. Result: Strong medical reasoning model
Multi-Task Fine-Tuning
Train on multiple tasks simultaneously to maintain general capabilities.
1
2
3
4
Dataset mix:
- 40%: Task-specific data
- 30%: General instruction-following
- 30%: Domain knowledge
Distillation During Fine-Tuning
Use larger model to generate training data for smaller model.
1
2
3
1. GPT-4 generates high-quality responses
2. Fine-tune Llama-7B on GPT-4 outputs
3. Result: Small model with large model capabilities
Common Pitfalls and Solutions
Problem 1: Catastrophic Forgetting
- Model loses general capabilities after fine-tuning
- Solution: Mix general data with task data (80/20 split)
Problem 2: Overfitting
- Perfect training accuracy, poor validation performance
- Solution: Early stopping, regularization, more data
Problem 3: Poor Data Quality
- Garbage in, garbage out
- Solution: Invest in data cleaning and validation
Problem 4: Insufficient Data
- Model doesn’t learn task patterns
- Solution: Data augmentation, use smaller model, or switch to RAG
Problem 5: Learning Rate Issues
- Too high: Training unstable, loss explodes
- Too low: Training too slow, convergence issues
- Solution: Use learning rate finder, start with 1e-4 to 5e-4 for fine-tuning
Cost-Benefit Analysis
| Aspect | Full Fine-Tuning | LoRA | QLoRA |
|---|---|---|---|
| Training Cost | \(\) | $$ | $ |
| Training Time | Days | Hours | Hours |
| GPU Required | A100 (80GB) | A100/4090 | 3090 (24GB) |
| Storage per Task | 100% (e.g., 14GB for 7B) | 1-5% (~100MB) | 1-5% (~100MB) |
| Performance | 100% | 95-98% | 90-95% |
| Best For | Maximum quality | Production use | Experimentation |
When to Fine-Tune vs Alternatives
Choose Fine-Tuning when:
- Need consistent, specific behavior/format
- Have sufficient quality training data (>1K examples)
- Task is well-defined and stable
- Want optimal inference speed
- Proprietary knowledge must be internalized
Choose Prompt Engineering when:
- Quick prototyping needed
- Limited/no training data
- Task requirements change frequently
- Budget constrained
Choose RAG when:
- Knowledge changes frequently
- Need source attribution
- Working with large document collections
- Information too large to fit in model
Combining Techniques: The Power of Hybrid Approaches
In real-world production systems, the most effective solutions often combine multiple techniques to leverage their complementary strengths. Rather than choosing a single approach, consider how different methods can work together to create more powerful and reliable LLM applications.
Common Hybrid Patterns
1. RAG + Prompt Engineering
The most common combination: Enhance RAG systems with carefully crafted prompts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Prompt Template:
"You are a helpful assistant with access to company documentation.
Rules:
1. Base your answer on the provided context
2. If information is not in context, say 'I don't have that information'
3. Cite sources using [Document name, page X] format
4. Be concise but complete
Context:
{retrieved_documents}
Question: {user_query}
Answer:"
Benefits:
- Better control over RAG outputs
- Improved citation behavior
- Reduced hallucination
- Consistent formatting
Use cases: Customer support bots, enterprise search, documentation assistants
2. Fine-Tuning + RAG
Domain-specific RAG: Fine-tune model on domain-specific reasoning patterns, then use RAG for facts.
Architecture:
1
2
3
4
5
6
7
8
9
1. Fine-tune base model:
- Domain-specific language (medical, legal, technical)
- Response formatting preferences
- Reasoning patterns
2. Deploy with RAG:
- Retrieves latest factual information
- Fine-tuned model interprets and synthesizes
- Best of both: domain expertise + current facts
Example (Medical Assistant):
1
2
3
4
5
6
7
8
9
10
11
Fine-tuning teaches:
- Medical terminology and reasoning
- Diagnostic thought patterns
- Professional communication style
RAG provides:
- Latest research papers
- Current treatment guidelines
- Drug interaction databases
Result: Expert medical assistant with up-to-date knowledge
Benefits:
- Domain expertise from fine-tuning
- Fresh information from RAG
- Better than either alone
3. Fine-Tuning + Prompt Engineering
Specialized models with dynamic control: Fine-tune for general task, use prompts for variations.
Example (Content Generation):
1
2
3
4
5
6
7
8
9
Fine-tune on:
- Brand voice and style
- Industry-specific writing patterns
- Format preferences
Use prompts to specify:
- Content type (blog, email, social post)
- Target audience (technical, general)
- Specific requirements per task
Benefits:
- Consistent base behavior (fine-tuning)
- Flexible customization (prompting)
- Reduced prompt complexity
4. Triple Combination: Fine-Tuning + RAG + Prompt Engineering
Full-stack approach for production-grade applications:
1
2
3
4
5
6
7
8
9
10
Layer 1 - Fine-Tuning:
↓ Domain expertise, reasoning style, output format
Layer 2 - RAG:
↓ Factual grounding, current information
Layer 3 - Prompt Engineering:
↓ Task-specific instructions, constraints
Final Output: High-quality, domain-expert, factually-grounded response
Example (Legal Research Assistant):
- Fine-tuned on:
- Legal reasoning patterns
- Citation formatting
- Professional legal writing
- RAG retrieves from:
- Case law databases
- Recent court decisions
- Relevant statutes
- Prompts specify:
- Jurisdiction
- Type of analysis needed
- Citation style
Result: Professional legal analysis with proper citations and current case law.
Decision Framework: Choosing Your Stack
Start Simple, Scale Complexity
Phase 1: Prototype (Week 1)
- Start with prompt engineering only
- Test if basic approach meets needs
- Quick iteration, no infrastructure
Phase 2: Enhance (Weeks 2-4)
- Add RAG if factual accuracy is insufficient
- Or fine-tune if specific behavior needed
- Evaluate improvement vs. complexity
Phase 3: Optimize (Month 2+)
- Combine techniques based on gaps
- Fine-tune for style, RAG for facts
- Advanced prompt engineering for control
Decision Matrix
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Need accurate facts about changing information?
├─ Yes → RAG (+ prompt engineering)
└─ No → Continue
Need specific style/format/reasoning?
├─ Yes → Fine-tuning (+ prompt engineering)
└─ No → Prompt engineering alone
Have proprietary knowledge to internalize?
├─ Yes → Fine-tuning
└─ No → RAG
Need both domain expertise AND current facts?
└─ Fine-tuning + RAG + Prompt Engineering
Real-World Hybrid Examples
Example 1: Customer Support Chatbot
Requirements:
- Know company products (500-page documentation)
- Handle returns, shipping, technical issues
- Friendly, helpful tone
- Cite relevant documentation
Solution:
1
2
3
4
5
6
7
8
9
10
11
12
Prompt Engineering:
- System prompt defining helpful persona
- Few-shot examples of good responses
RAG:
- Index product documentation
- Retrieve relevant sections per query
- Include order history, user data
Optional Fine-tuning:
- If brand voice is very specific
- If handling complex reasoning (troubleshooting)
Why this works: RAG handles dynamic product info, prompts control tone, fine-tuning (if needed) for company-specific reasoning.
Example 2: Code Documentation Assistant
Requirements:
- Understand company’s codebase
- Explain functions, generate examples
- Follow coding standards
- Reference actual code
Solution:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Fine-tuning:
- Train on company's coding patterns
- Learn internal frameworks and conventions
- Understand architecture decisions
RAG:
- Index entire codebase
- Retrieve relevant functions/files
- Include Git history, comments
Prompt Engineering:
- Specify language, framework
- Request runnable examples
- Format code properly
Why this works: Fine-tuning internalizes coding style, RAG provides actual code context, prompts guide specific outputs.
Example 3: Research Paper Summarizer
Requirements:
- Summarize academic papers
- Extract methodology, findings
- Technical accuracy essential
- Multiple paper comparison
Solution:
1
2
3
4
5
6
7
8
9
10
11
12
13
RAG:
- Index paper database
- Retrieve relevant sections
- Cross-reference papers
Prompt Engineering:
- Structured summary template
- Specify sections to extract
- Comparison format for multiple papers
Optional Fine-tuning:
- If specific field (e.g., only biomedical papers)
- Learn field-specific summarization patterns
Why this works: RAG ensures accuracy to source material, prompts structure output, fine-tuning adds domain expertise.
Implementation Best Practices
1. Measure Each Component
1
2
3
4
5
6
7
8
Baseline: Prompt engineering only
↓ Measure: Accuracy, latency, cost
Add RAG
↓ Measure: Improvement in accuracy, added latency
Add Fine-tuning
↓ Measure: Improvement vs. cost and complexity
Track metrics:
- Response quality (human eval or LLM-as-judge)
- Latency (p50, p95, p99)
- Cost per query
- User satisfaction
2. Optimize the Pipeline
1
2
3
4
5
6
7
8
9
Slow pipeline:
Query → Retrieval (200ms) → Reranking (300ms) → LLM (2000ms)
Total: 2500ms
Optimized:
Query → [Parallel] Retrieval (200ms) + Cache check
→ Reranking (150ms, optimized)
→ LLM (1000ms, fine-tuned smaller model)
Total: 1350ms
3. Cache Aggressively
1
2
3
4
5
6
7
8
9
10
# Cache common queries
if query in cache and cache_fresh(query):
return cache[query] # <10ms
# Cache retrieved contexts
if query_embedding in context_cache:
context = context_cache[query_embedding]
else:
context = retrieve_and_rank(query)
context_cache[query_embedding] = context
4. Monitor and Iterate
1
2
3
4
5
6
7
8
9
10
Week 1: Deploy RAG + Prompt Engineering
↓ Collect user feedback and edge cases
Week 4: Analyze failure modes
↓ Are they RAG retrieval issues? → Improve indexing
↓ Are they response quality issues? → Consider fine-tuning
Month 3: Fine-tune on collected data
↓ Real user queries and preferences
↓ High-quality training data
Cost Optimization Strategies
Tiered Approach
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Simple queries (60% of traffic):
→ Small model + prompt engineering
→ Cost: $0.001 per query
Complex queries (35% of traffic):
→ Large model + RAG
→ Cost: $0.01 per query
Very complex queries (5% of traffic):
→ Fine-tuned large model + RAG + advanced prompting
→ Cost: $0.05 per query
Average cost: $0.006 per query vs. $0.01 for all-complex
Savings: 40%
Intelligent Routing
1
2
3
4
5
6
7
8
9
def route_query(query, user_history):
complexity = estimate_complexity(query)
if complexity < 3:
return simple_pipeline(query) # Prompt only
elif complexity < 7:
return rag_pipeline(query) # RAG + prompt
else:
return premium_pipeline(query) # Fine-tuned + RAG + prompt
Choosing Between Fine-Tuning and RAG:
The best choice depends on your specific needs:
Task Focus:
Fine-tuning: Well-suited for tasks requiring high accuracy and control over the LLM’s output (e.g., sentiment analysis, code generation).
RAG: Ideal for tasks where access to external knowledge is crucial for comprehensive answers (e.g., question answering, information retrieval).
Prompt Engineering: This is the art of crafting clear instructions for the LLM. It can be used on its own or to enhance fine-tuning and RAG. Well-designed prompts can significantly improve the quality and direction of the LLM’s output, even without retraining.
Data Availability:
Fine-tuning: Requires a well-curated dataset specific to your task.
RAG: Works with a knowledge source that may be easier to obtain than a specialized dataset.
Prompt Engineering: This doesn’t require any specific data – just your understanding of the LLM and the task.
Computational Resources:
Fine-tuning: Training can be computationally expensive.
RAG: Retrieval and processing can be resource-intensive, but less so than fine-tuning in most cases.
Prompt Engineering: This is the most lightweight approach, requiring minimal computational resources.
Prompting vs Fine-tuning vs RAG
In this section, we used the table as below to help you see the differences and decide which method might be best for what you need.
| Feature | Prompting | Finetuning | Retrieval Augmented Generation (RAG) |
|---|---|---|---|
| Skill Level Required | Low: Requires a basic understanding of how to construct prompts. | Moderate to High: Requires knowledge of machine learning principles and model architectures. | Moderate: Requires understanding of both machine learning and information retrieval systems. |
| Pricing and Resources | Low: Uses existing models, minimal computational costs. | High: Significant computational resources needed for training. | Medium: Requires resources for both retrieval systems and model interaction, but less than finetuning. |
| Customization | Low: Limited by the model’s pre-trained knowledge and the user’s ability to craft effective prompts. | High: Allows for extensive customization to specific domains or styles. | Medium: Customizable through external data sources, though dependent on their quality and relevance. |
| Data Requirements | None: Utilizes pre-trained models without additional data. | High: Requires a large, relevant dataset for effective finetuning. | Medium: Needs access to relevant external databases or information sources. |
| Update Frequency | Low: Dependent on retraining of the underlying model. | Variable: Dependent on when the model is retrained with new data. | High: Can incorporate the most recent information. |
| Quality | Variable: Highly dependent on the skill in crafting prompts. | High: Tailored to specific datasets, leading to more relevant and accurate responses. | High: Enhances responses with contextually relevant external information. |
| Use Cases | General inquiries, broad topics, educational purposes. | Specialized applications, industry-specific needs, customized tasks. | Situations requiring up-to-date information, and complex queries involving context. |
| Ease of Implementation | High: Straightforward to implement with existing tools and interfaces. | Low: Requires in-depth setup and training processes. | Medium: Involves integrating language models with retrieval systems. |
Conclusion: Building Effective LLM Applications
The landscape of LLM adaptation techniques offers a powerful toolkit for developers and organizations looking to harness the potential of large language models. Understanding when and how to apply prompt engineering, RAG, and fine-tuning—individually or in combination—is crucial for building effective, efficient, and cost-optimized AI applications.
Key Takeaways
1. Start Simple, Scale Smartly
- Begin with prompt engineering for rapid prototyping
- Add complexity only when justified by measurable improvements
- Each technique adds cost, latency, and maintenance burden
2. Match Technique to Problem
- Prompt Engineering: General tasks, rapid iteration, zero budget
- RAG: Dynamic knowledge, source attribution, large document collections
- Fine-Tuning: Specialized behavior, consistent style, domain expertise
- Hybrid: Production systems requiring multiple capabilities
3. Data is the Differentiator
- Prompt engineering: No data needed
- RAG: Quality of retrieval determines quality of outputs
- Fine-tuning: Quality and quantity of training data is critical
- All techniques: Continuous evaluation and improvement is essential
4. Consider Total Cost of Ownership
| Technique | Initial Cost | Maintenance | Scalability |
|---|---|---|---|
| Prompt Engineering | $ | Low | High |
| RAG | $$ | Medium | Medium |
| Fine-Tuning | $$$ | High | High |
| Hybrid | \(\) | High | Medium |
Final Thoughts
The field of LLM adaptation is rapidly evolving. What requires fine-tuning today might be achievable with advanced prompting tomorrow. What needs RAG now might be internalized in future model versions. The key is to:
- Stay informed about new techniques and models
- Measure rigorously - data beats intuition
- Iterate quickly - fail fast, learn faster
- Build flexibly - design systems that can adapt as techniques improve
- Focus on value - technique choice matters less than solving user problems
By understanding these fundamental techniques and their trade-offs, developers can build LLM applications that are not only powerful and accurate but also efficient, maintainable, and cost-effective. The future of AI development lies not in choosing a single approach, but in thoughtfully combining techniques to create systems that leverage the best of what each has to offer.